
Architecting for Success: Essential System Design Principles for Developers
Niraj SalotJanuary 31, 2025
Share this article




In the IT industry, it is a common yet critical mistake to dive straight into coding when starting a new project. However, this approach can lead to inefficiencies, technical debt, and costly rework down the line.
Before developing a new application or product, it is essential to consider key architectural aspects from the outset. By addressing these fundamental questions—either internally or with the customer—we can ensure a well-structured, scalable, and future-ready solution.
Let’s explore these crucial considerations in detail to lay the foundation for a robust and successful application.
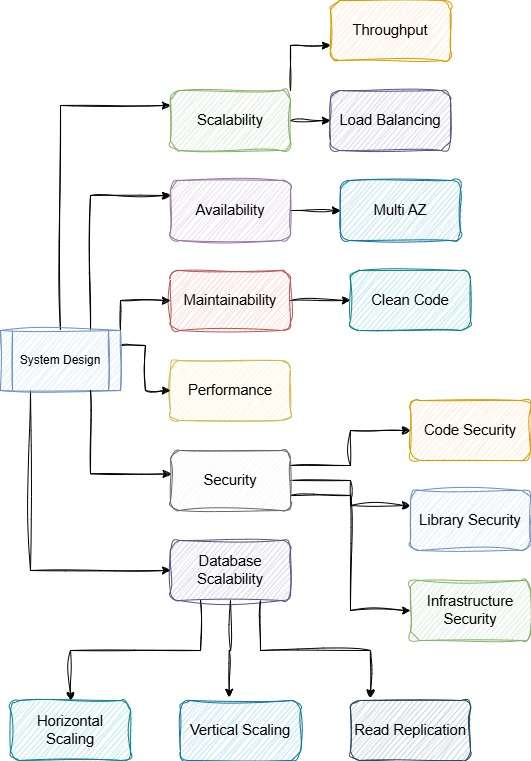
Scalability refers to the ability of a system to handle increased load by adding resources. It ensures that the system can grow to accommodate more users or data without compromising performance. Scalability can be achieved through horizontal scaling (adding more machines) or vertical scaling (adding more power to existing machines). It is crucial for applications expecting growth in user base or data volume. Proper planning and architecture are essential to ensure seamless scalability. Cloud-based solutions often provide flexible scalability options.
Availability ensures that a system is operational and accessible when needed. High availability is achieved through redundancy, failover mechanisms, and robust infrastructure. It minimizes downtime and ensures continuous service, which is critical for user satisfaction and business continuity. Techniques like load balancing and distributed systems enhance availability. Regular maintenance and monitoring are necessary to maintain high availability levels.
Maintainability refers to the ease with which a system can be modified, updated, or repaired. A maintainable system has clean, well-documented code and follows best practices. It reduces the cost and effort required for future changes and bug fixes. Modular design and consistent coding standards improve maintainability. Regular code reviews and refactoring help keep the system maintainable over time.
Performance measures how efficiently a system operates under a given workload. It includes response time, throughput, and resource utilization. Optimizing performance involves tuning the code, database, and infrastructure. Caching, load balancing, and efficient algorithms can enhance performance. Monitoring tools help identify and address performance bottlenecks. High performance is essential for user satisfaction and system reliability.
Security protects the system from unauthorized access, data breaches, and other threats. It involves implementing authentication, authorization, encryption, and secure coding practices. Regular security audits and updates are necessary to address vulnerabilities. Security measures should be integrated into every layer of the system. Protecting user data and ensuring compliance with regulations are critical aspects of security.
Code security involves writing secure code to prevent vulnerabilities like SQL injection, XSS, and buffer overflows. Best practices include input validation, using parameterized queries, and following secure coding guidelines. Regular static code analysis and security testing help identify potential threats early. Secure coding standards such as OWASP Top 10 should be followed.
Library security ensures that third-party dependencies used in an application are safe and up-to-date. Regularly updating libraries and checking for known vulnerabilities using tools like Snyk, Dependabot, or OWASP Dependency-Check is essential. Avoid using deprecated or unmaintained libraries that may introduce security risks. Always verify the source and integrity of open-source dependencies before integrating them.
Infrastructure security protects the underlying systems, networks, and cloud environments from unauthorized access and threats. This includes enforcing network segmentation, enabling firewalls, securing API gateways, and implementing access controls like IAM policies. Regular security audits, patch management, and monitoring with SIEM tools help detect and mitigate potential threats. Encrypting data at rest and in transit ensures additional protection against breaches.
Data migration involves transferring data from one system to another. It requires careful planning to ensure data integrity and minimal downtime. Testing and validation are crucial to avoid data loss or corruption. Automation tools can streamline the migration process. Proper documentation and backup strategies are essential for successful data migration.
Language support ensures that the system can handle multiple languages for a global user base. It involves localization and internationalization of the application. Proper encoding and character sets are necessary to support different languages. Language support enhances user experience and accessibility. Regular updates and testing are required to maintain language compatibility.
Latency refers to the delay before a transfer of data begins following an instruction. Low latency is crucial for real-time applications and user satisfaction. Optimizing network performance and reducing processing time can minimize latency. Techniques like content delivery networks (CDNs) and efficient algorithms help reduce latency. Monitoring tools help identify and address latency issues.
Back-up requirements ensure that data is regularly copied and stored securely. Regular backups protect against data loss due to hardware failure, cyber-attacks, or human error. Automated backup solutions and off-site storage enhance data security. Testing backup integrity and having a recovery plan are essential. Proper documentation and compliance with regulations are necessary for backup strategies.
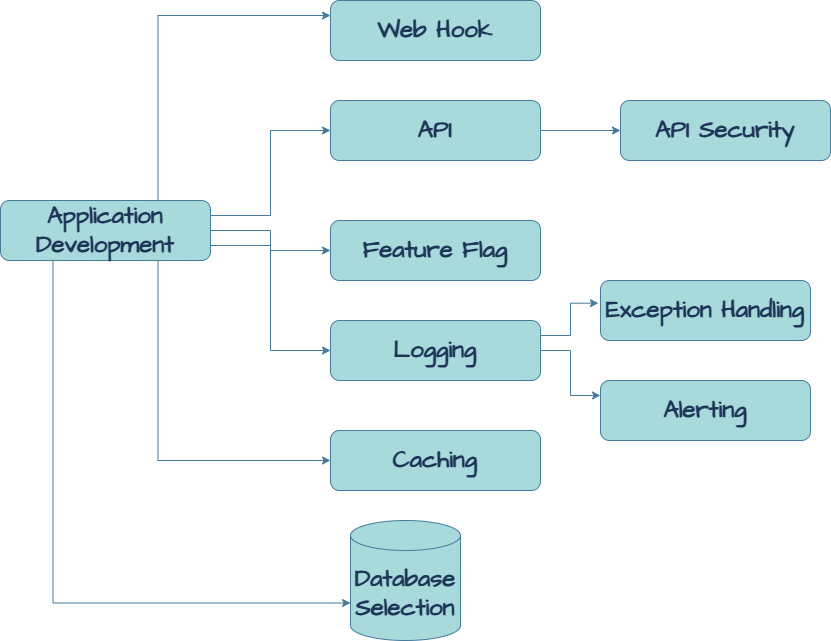
Caching stores frequently accessed data to reduce load times and improve performance. It can be implemented at various levels, including application, database, and network. Effective caching strategies enhance user experience and system efficiency. Cache invalidation and consistency are important considerations. Monitoring and tuning cache performance help maintain optimal system operation.
Exception handling manages errors and unexpected conditions in the system. Proper exception handling ensures that the system can recover gracefully from errors. It improves system reliability and user experience. Logging and monitoring exceptions help identify and fix issues. Best practices include using specific exception types and providing meaningful error messages.
Monitoring involves tracking system performance, availability, and health. It helps identify and address issues before they impact users. Real-time monitoring tools provide insights into system behaviour. Regular monitoring ensures optimal performance and reliability. Alerts and dashboards help teams respond quickly to potential problems.
Alerting notifies teams of potential issues or system anomalies. It ensures timely response to incidents, minimizing downtime and impact. Configuring appropriate thresholds and escalation policies is crucial. Effective alerting reduces noise and focuses on critical issues. Integration with monitoring tools enhances the effectiveness of alerting systems.
Logging records system events and activities for analysis and troubleshooting. It provides a historical record of system behaviour and errors. Proper log management ensures that logs are stored securely and efficiently. Log analysis helps identify patterns and root causes of issues. Best practices include using structured logging and rotating log files.
Database scalability ensures that the database can handle increased load and data volume. Techniques include horizontal scaling (adding more servers) and vertical scaling (increasing server capacity). Partitioning and read replication improve performance and availability. Proper indexing and query optimization enhance database efficiency. Regular monitoring and maintenance are essential for scalable databases.
Horizontal scaling involves adding more machines to distribute the load. It improves system performance and availability. Load balancing ensures even distribution of traffic across servers. Horizontal scaling is cost-effective and flexible. It is suitable for systems expecting significant growth in users or data.
Vertical scaling involves adding more resources (CPU, RAM) to existing machines. It is simpler to implement than horizontal scaling. Vertical scaling improves performance for applications with increasing resource demands. However, it has limitations based on the maximum capacity of a single machine. It is suitable for systems with moderate growth expectations.
Partitioning divides a database into smaller, more manageable pieces. It improves performance and manageability by distributing data across multiple servers. Partitioning can be based on criteria like range, hash, or list. It enhances query performance and reduces contention. Proper planning and implementation are essential for effective partitioning.
Read replication involves creating copies of the database for read operations. It improves performance by distributing read queries across multiple servers. Read replication enhances availability and fault tolerance. It is useful for applications with heavy read loads. Proper synchronization and monitoring ensure data consistency.
Database sharding is a horizontal partitioning technique where a large database is split into smaller, more manageable pieces called shards. Each shard is an independent database, containing a subset of the overall data. This helps improve performance, scalability, and availability.
Indexing improves database query performance by creating data structures for faster data retrieval. Proper indexing reduces query execution time and resource usage. Different types of indexes (e.g., B-tree, hash) are suitable for different scenarios. Regular maintenance and optimization of indexes are necessary. Over-indexing can lead to increased storage and maintenance overhead.
Cloud-native development involves building applications specifically for cloud environments. It leverages cloud services and infrastructure for scalability and flexibility. Microservices, containers, and orchestration tools like Kubernetes are common in cloud-native development. It enhances agility, resilience, and cost-efficiency. Continuous integration and delivery (CI/CD) pipelines are integral to cloud-native development.
Cloud provider-independent development ensures that applications can run on any cloud platform. It avoids vendor lock-in and enhances flexibility. Using open standards and portable technologies is key. Containerization and orchestration tools help achieve provider independence. It allows businesses to switch providers or use multi-cloud strategies without significant rework.
Unlimited storage refers to the ability to store vast amounts of data without constraints. Cloud providers often offer scalable storage solutions. It supports data-intensive applications and big data analytics. Proper data management and archiving strategies are necessary. Unlimited storage enhances flexibility and supports business growth.
Reporting involves generating and analysing data to provide insights and support decision-making. Effective reporting tools and dashboards enhance data visibility. Automated reporting ensures timely and accurate information. Customizable reports cater to different user needs. Proper data integration and validation are essential for reliable reporting.
Choosing between RDBMS and NoSQL depends on data structure, consistency, and scalability needs. RDBMS (e.g., PostgreSQL, MySQL) is ideal for structured data and transactional integrity, while NoSQL (e.g., MongoDB, DynamoDB) suits flexible, high-velocity, and distributed data use cases. Consider factors like ACID compliance, indexing, replication, and query performance when making a decision. A hybrid approach may be necessary for complex systems requiring both structured and unstructured data handling.
Efficient database connection pooling optimizes performance by reusing active connections rather than creating new ones for each request. This reduces latency, improves resource utilization, and prevents database exhaustion under heavy load. Implementing connection pooling configurations like size limits, idle timeouts, and automatic reconnections ensures system stability. Popular libraries like HikariCP (Java) or PgBouncer (PostgreSQL) help manage efficient pooling.
Message queues (e.g., RabbitMQ, Kafka, AWS SQS) enable decoupling between services, ensuring reliability and scalability. Choosing the right messaging system depends on use cases like event-driven architecture, real-time streaming, or asynchronous processing. Factors such as message durability, ordering, and delivery guarantees (at-most-once, at-least-once, exactly-once) must be considered. Ensuring proper monitoring and dead-letter queue management prevents message loss and system failures
Synchronous execution ensures sequential processing, making it easier to manage dependencies but potentially leading to bottlenecks. Asynchronous execution improves scalability by handling tasks concurrently, reducing response times in high-traffic environments. Use cases like database transactions often require synchronization, while background tasks, notifications, or heavy computations benefit from asynchronization. Implementing async patterns (e.g., event-driven systems, job queues) optimizes system efficiency.
Securing APIs involves implementing authentication, authorization, and encryption to prevent unauthorized access and data breaches. Techniques like OAuth 2.0, JWT, and API keys help control access, while rate limiting and WAF (Web Application Firewall) protect against abuse. Encrypting data in transit (TLS) and at rest, along with input validation and logging, strengthens security. Regular penetration testing and adherence to security standards like OWASP API Security Top 10 enhance protection.
Comprehensive API documentation ensures easy integration and adoption by developers. Using tools like OpenAPI (Swagger), Postman, or Redoc improves clarity with detailed endpoints, request-response examples, and authentication methods. Keeping documentation version-controlled and updated with change logs prevents inconsistencies. Providing interactive documentation with API sandbox environments enhances usability.
Webhooks enable real-time event-driven communication between systems by pushing data to subscribed endpoints. Defining webhook payload structure, security (HMAC signatures, IP whitelisting), and retry mechanisms ensures reliability. Implementing event filtering and logging helps monitor webhook performance and failure handling. Scalable webhook delivery can be enhanced using message queues or background job processing.
Feature flags allow controlled feature rollouts, enabling A/B testing, canary releases, and quick rollbacks. Implementing feature toggles helps minimize deployment risks and ensures dynamic configuration without redeployment. Solutions like LaunchDarkly, Unleash, or custom flag management in databases enhance flexibility. Proper flag cleanup and lifecycle management prevent technical debt.
A robust deployment strategy ensures minimal downtime and risk-free releases. Blue-Green, Canary, and Rolling Deployments help reduce service disruptions and allow progressive rollouts. Automating CI/CD pipelines with rollback mechanisms ensures fast recovery from failures. Containerization (Docker, Kubernetes) and Infrastructure as Code (Terraform, AWS CloudFormation) enable scalable and consistent deployments.
Defining a maintenance and downtime policy ensures transparency and minimizes business impact. Scheduled maintenance windows should be communicated in advance with fallback mechanisms in place. Implementing graceful degradation strategies and redundant failover systems prevents complete service outages. Monitoring tools like Prometheus, Datadog, or AWS CloudWatch help detect and resolve issues proactively.
A public or internal status page enhances transparency by providing real-time system health updates. Services like StatusPage.io, Better Uptime, or custom-built dashboards help communicate incidents and planned maintenance. Integrating automatic alerts and historical uptime tracking builds trust with users. Offering API access for status monitoring enhances integration capabilities.
 Niraj Salot
Niraj Salot
Niraj Salot, with 20+ years of expertise in software architecture, specializes in delivering robust enterprise applications. His cloud optimization skills help clients cut costs while maximizing performance. As a key leader at NextGenSoft, he drives scalable, efficient, and high-performing solutions.

Microservices vs Monoliths: Making the Right Choice In today’s software development landscape, choosing between Microservices vs Monoliths is a critical decision that can significantly impact your project’s success. This article explores both approaches, their strengths and weaknesses, and provides guidance on making the right choice for your specific needs. Understanding Microservices vs Monoliths in Modern […]

Product Architecture: Why It Matters in SaaS and Beyond In today’s fast-evolving digital world, organizations must consistently deliver high-quality products at speed. A well-defined architecture and clear product definition form the foundation of a successful offering. Without a robust product architecture, companies face inefficiencies, rising costs, and even the risk of failure. This guide explains […]